| Sociolingüística catalana |
| Evolució dels usos i de les representacions socials de les llengües a Catalunya (1993-2000), per Ernest Querol | ||||
| CONTINUA |
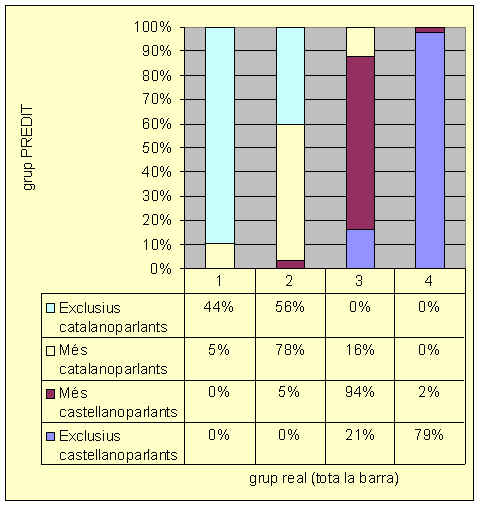
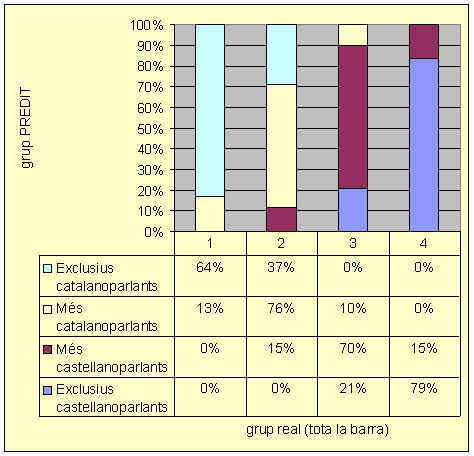
El quadre 7 (vegeu quadre) ens mostra quins són els segments que permeten identificar millor cada grup (9). El primer d'aquests és la identitat "espanyola / no-espanyola". El segon factor que divideix els grups és l'autocategorització com a "catalanoparlant / no-catalanoparlant", juntament amb la representació del catalŕ. En el tercer nivell trobem les variables: xarxa social catalana, representació del catalŕ i representació del castellŕ. Com veiem, aquest mčtode ens permet considerar altres variables a banda de les que havíem proposat en les hipňtesis (la "identitat espanyola / no-espanyola" i l'autocategorització com a "catalanoparlant / no-catalanoparlant") i, justament, les trobem en els dos llocs més importants. En el quadre 8 (vegeu quadre), referit a l'any 2000, tornem a trobar les mateixes tres primeres variables. Només en un tercer nivell es produeixen petits canvis, com ara l'ordre en quč apareixen les xarxes i la representació. Fet que ens mostra l'estabilitat de les característiques dels grups lingüístics. És molt interessant comparar les puntuacions obtingudes en les dues recerques perquč ens mostren l'evolució dels grups lingüístics, perň, malauradament, no disposem de prou espai per a comentar-les ara. 4.3.1. Les previsions de pertinença a un grup lingüístic El model que hem exposat ens permet predir el grup al qual pertany un alumne sense tenir les informacions que ens han dut a fer aquesta classificació (10). El del 1993 arriba a predir un 83,8% dels casos classificats i en cap cas fa un error amb un grup que no sigui veí. Al 2000, el nivell d'encerts baixa al 72.3%, perň tampoc no comet cap error que no sigui amb un grup contigu, per tant, aquests percentatges tan alts mostren la validesa del model que hem utilitzat. Vegem-ho en els quadres 9 i 10. Quadre 9. Nivell d'encert (83,8%) del model (1993)
Quadre 10. Nivell d'encert (72,3%) del model (2000)
|